

What is RAG, Benefits, Use Cases & How Does It Work?
- December 2, 2024
- 9 mins read
- Listen

Table of Content
Customer service is evolving in all industries as companies are investing more in chatbots. However, some chatbots are still relying on old technologies such as rule-based models or have just started to switch to Large Language Models (LLMs).
LLMs offer a great number of features needed for a business but they have their shortcomings. Multi-language conversations are still limited for LLMs, as we still rely on manual translation data to be inputted to the chatbot. Also, the information provided by chatbots can be incorrect or outdated due to hallucinations and lack of real-time data.
To solve these issues and provide better customer support, Retrieval-Augmented Generation (RAG) has been created, a process that can be the solution to current LLM models. So, let’s dive into what RAG is, how it works, and all the benefits and use-cases that have made quite the commotion in the AI space.
What is Retrieval-Augmented Generation (RAG)?
In short, Retrieval-Augmented Generation (RAG) is a technique that integrates trusted and varied data sources with up-to-date information in your LLM-based chatbots. It is the next evolution of Generative AI that enhances LLM models to address its shortcomings.
The general idea of RAG is to retrieve real-time data and information from external sources and provide chatbots with the necessary tools to offer coherent and accurate information.
How Does RAG Work?
To understand how RAG works, there are some concepts that you will need to know about. While data can be found in PDFs, other documents, websites, etc., Generative AIs use a type of Vector Data called Embeddings to create their solution.
Embeddings are numerical versions of the data parsed from their respective sources. Using an Embedding Model or System, these vector data are created and stored in a Vector Database. Below is a basic workflow how RAG works in practice.
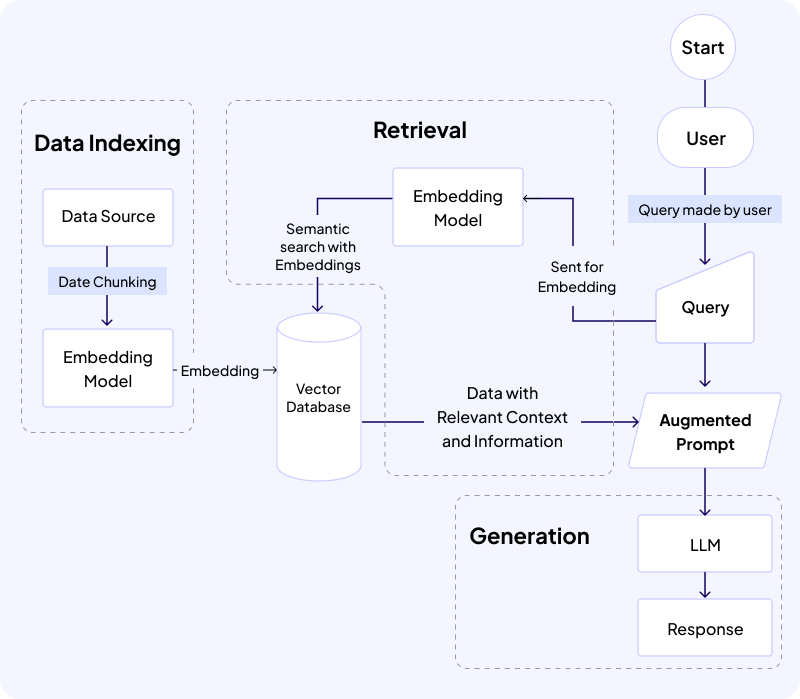
There are many processes that take place for RAG to be fully implemented for an LLM. These phases are:
Continuous Data Indexing
A huge part of RAG is getting relevant and updated information, and this is done through the Data Indexing process. In this case, external sources are set up that can be indexed by breaking down the documents or information into Embeddings and storing them in the database.
How the process works is as follows:
- It chooses a data source like a document, website, or another database.
- Breaks the content of those sources into chunks
- Passes the chunks to an Embedding model that converts them into vectors
- Stores in a vector database
The Data Indexing process can either be automated or manually controlled by developers to update their data in the vector database. However, this process needs to occur frequently, as outdated data makes the whole process of RAG redundant.
Using this vector database, your LLMs become more capable of generating updated and detailed responses.
Retrieval
The Retrieval process starts when the user enters a query for the Chatbot. What RAG then does is send this query to an Embedding Model to turn to Embeddings and do a semantic search on the Vector Database. Here are the steps of this process.
- Receive Query from User
- Passes the Query to an Embedding Model
- Query is turned into Embeddings
- A Semantic Search is done to cross-check data in the database with the query.
- Relevant chunks of data are retrieved from the database and sent to the prompt.
Using the semantic search, RAG is able to identify relevant content and pass it along to the prompt. This way, an Augmented Prompt is generated using the Query and the Relevant content.
Augmented Prompts
After the Retrieval process is complete, RAG combines the relevant information gathered and the query to form a unique prompt. This prompt is more specific and has much more context inside it for the LLM to make use of.
Generation
With the LLM provided with an Augmented Prompt, it can use all this information to provide an informed response for the user. The query + context allows an LLM to answer the question in a more informed manner, increasing the accuracy of the information provided. That way, your chatbots operate at a higher level down the line.
Six Key Benefits of RAG
There are many benefits for RAG that you will find. For this blog, we have listed six of the most important benefits of RAG.
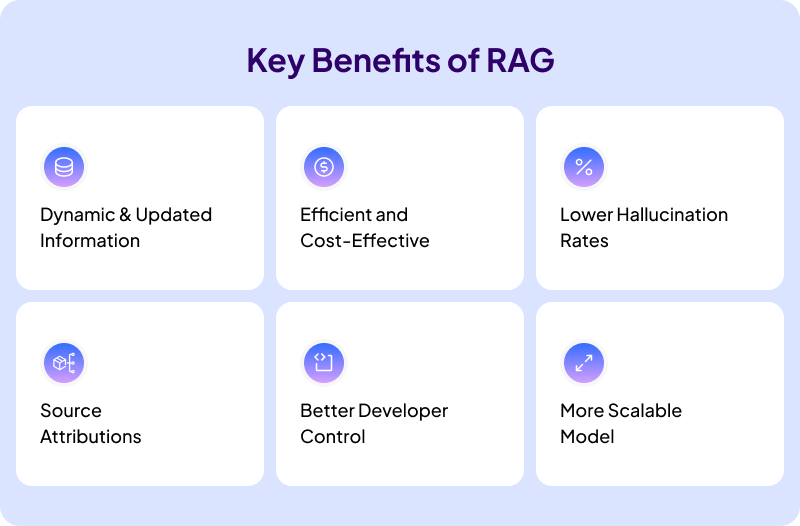
1. Dynamic and Updated Information
One of the biggest selling points of RAG is that it will allow a LLM Chatbot to provide accurate and up-to-date responses. Without the use of real-time information, there would be no difference between a basic LLM model, and a RAG implement one.
2. Efficient and Cost-Effective
RAG operates efficiently as it has a Data Indexing process that constantly parses through data and stores it in a database. This already makes RAG contain more correct information than a general LLM knowledge base. Even then, you can just exclude any incorrect information from a source with ease if needed.
Furthermore, this updating of information through Indexing can occur continuously, resulting in no extra costs. Hence, RAG is more efficient and cost-effective by having all this data on hand without having to spend more.
3. Lower Hallucination Rates
LLMs have a huge tendency to hallucinate, given their limited knowledge base, making this one of the biggest flaws of generative AI. Using RAG, hallucinations can be reduced by a considerable margin due to the Retrieval and Augmented Prompt process.
Using both processes, RAG is able to provide a better and more detailed prompt to the LLM. This way, the LLM has a reference point they can use and provide responses based on that.
Also, since RAG is already providing so much relevant information and such, the LLM has a lower margin of error. Hence, utilizing RAG for LLMs is the best way to reduce hallucination rates.
4. Source Attributions
When RAG provides data to the LLM, it also comes with a link or citation to the resource used in question. This provides further context to a user and allows for some self-support they may need in the future. Also, it legitimizes the answers generated, as there is another source backing up what your LLM said.
5. Better Knowledge Control
Using RAG, you can set or decide which sources it will index or use for the LLM. Since the knowledge sources are vetted by you, you can use these resources to direct the LLM to give responses based on that. Thus, giving you more control over what the LLM says.
6. More Scalable
It’s a good question as to how RAG makes LLMs more scalable and there are a few reasons why. For one, you are providing external sources to RAG, and they are utilizing and implementing it as needed. That also means there are no real limits to how much you can provide.
Furthermore, as you grow your business in other industries, you don’t have to start anew. You can just implement the information you need into RAG and create more use cases in the process.
Use Cases of RAG
There are many use cases for RAG across many industries. Thus, here are some key ones.
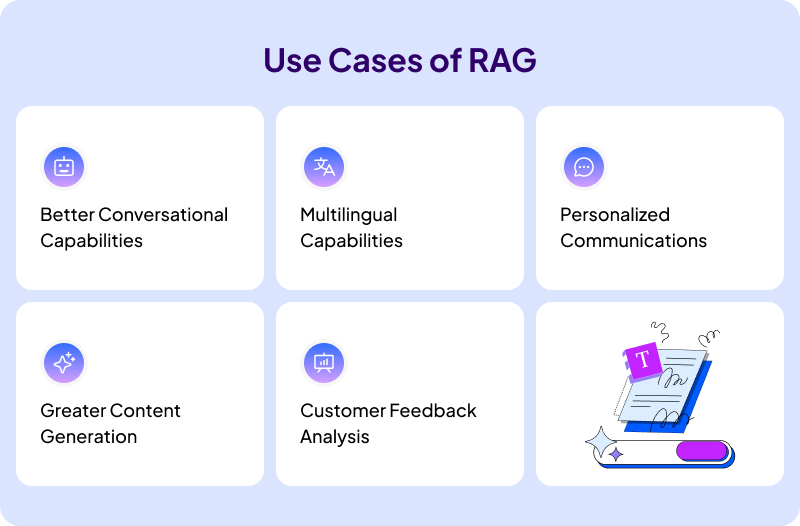
Better Conversational Capabilities
In simple words, RAG makes Chatbots better in terms of conversations. With the Augmented Prompts provided to LLMs, a chatbot is more capable of providing better and more insightful information. So not only are the responses correct, but they are also more contextual.
Using REVE Chat’s chatbots, you can utilize the power of RAG and provide your customers with better information and responses about your products, services, and your business in general.
Multilingual Capabilities
RAG is capable of sifting through documents of all languages utilizing NLP (Natural Language Processing). As all data is just numbers for RAG, they can parse, compare, search, and provide information in all languages provided the LLM is trained to handle the language.
If you think it requires a lot of work, well that’s not exactly accurate. All RAG has to do is create different vector databases for the different languages and simply compare based on what language the query is coming in. As mentioned before, providing sources for RAG is up to you and they automatically index it for any future use.
This creates a space for multilingual chatbots to be utilized for your business. Our chatbots are equipped with all the multilingual capabilities you need utilizing both RAG and NLP.
Personalized Communications
While we provided a basic workflow for RAG, it has capabilities to go beyond that. You can not only search with the query, but you can also store the query for future use. That way, you remember what the user asked for and their information.
Hence, during the Retrieval process, you can make use of this information to provide more personal responses to a user. Our chatbots utilize RAG for this purpose as we believe that providing personalized support is key in the customer service sector.
Greater Content Generation
RAG improves the content generation process by a huge margin. Not only is it providing better context and responses as previously mentioned, but it’s also providing more personalized recommendations.
Utilizing all of that detailed information from across the web that you vetted, you can enhance your business’s capabilities to provide better and more personalized content.
Customer Feedback Analysis
With RAG, you can create a feedback loop, where users can provide feedback, and you can store it in your database. This allows you to collect different kinds of feedback like customer satisfaction, how they feel about your products, and more.
Utilizing all this feedback, you can address the pain points of customers by identifying the problems using RAG. For a business, this is crucial as it allows your company to improve.
REVE Chat’s products utilize the customer feedback system in order to further push our customer service capabilities to greater heights.
Conclusion
By utilizing RAG, businesses can take their content generation, chatbots, and other generative processes to a whole new level. RAG diversifies the LLM industry by a lot, providing more accuracy and fewer hallucinations.
Through all of these processes, RAG is a premier technique used for LLMs, and REVE Chat is at the forefront of these implementations for customer service.
You can try our RAG-enabled customer service right now by signing up and experiencing the best support capabilities you can have for your business.
Frequently Asked Questions
RAG stands for Retrieval-Augmented Generation.
RAG is a technique that allows you to improve Large Language Models (LLMs) to greater heights. It improves the Generative AI capabilities of providing better and more informed information.
RAG is used in several industries to improve customer support, content generation and communication methods. This allows businesses to scale better and be more efficient and cost-effective with less error rates.
A Chatbot that is empowered by RAG is generally called a RAG Chatbot. Utilizing the capabilities of RAG, a chatbot can improve their customer service capabilities by a considerable margin.
RAG Chatbots are accurate as they provide more up-to-date information with better context. Through RAG, chatbots can generate better and more informed responses for customers.


